
Self-Describing Data Asset
A flexible data model not defined by the storage environment but by the enriched data and metadata
Interoperability
Self-describing data assets include metadata that provides context about the data, such as its structure, format, and meaning. This makes it easier to integrate and use data across different systems and applications
and Consistency
Advanced Analytics
Enhance Data Reliability and Reutilization Making it Future Proof
Rigid or predefined database models are limiting the ability to interrogate data later on. This restricts the capability to flexibly query data assets, to share data with relevant parties and to maximize downstream data value.
SciY self-describing data asset represent a new data enrichment, standardization and storage paradigm, based on the concept of data models associated to individual items leveraging a common, extensive ontology, keeping full data model flexibility through data life cycle. Below there is an application example.
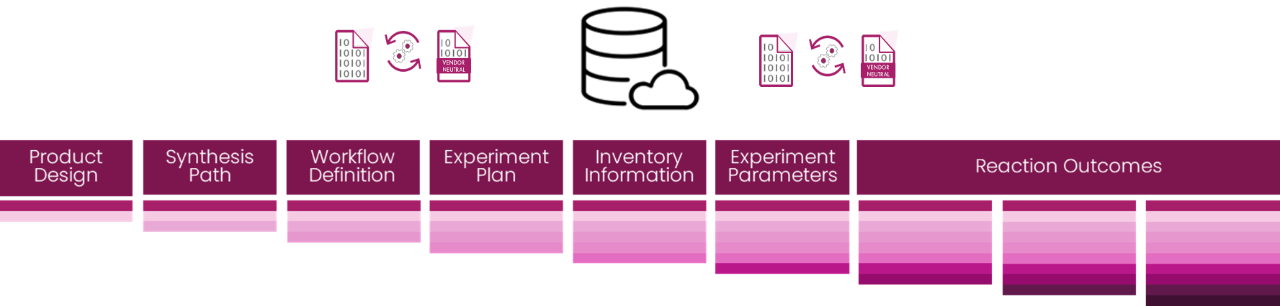
Features
- Storage of metadata and files/documents, continuous metadata enrichment
- Many different data entities and types supported (small and biomolecules, spectral/instrument data, alphanumerical data, etc.)
- Data standardization – (translation ontologies)
- Cloud data storage
- FAIR data format, (vendor neutral, JSON based)
- RESTful API, making all data available through services/microservices to sources and consumers
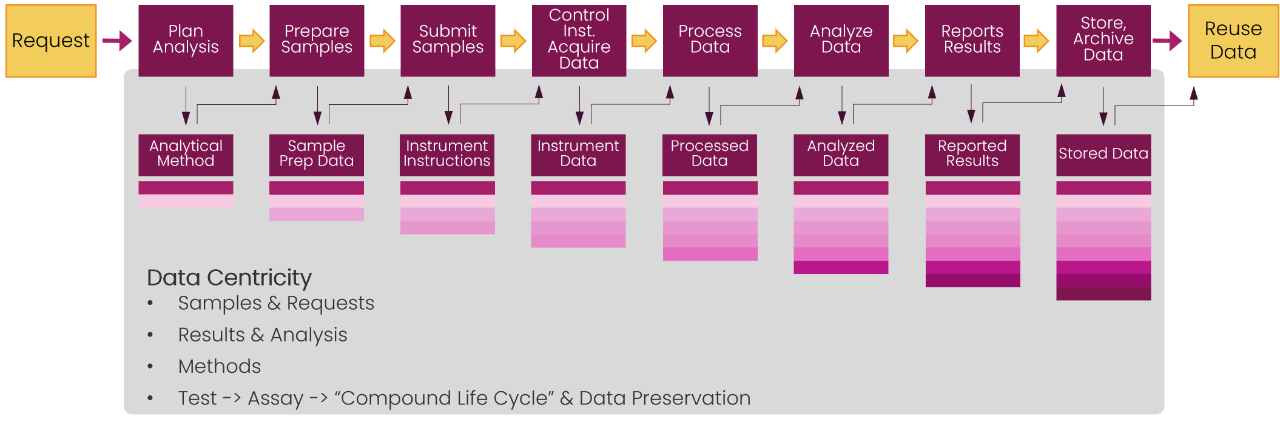
Example 2 illustrating the principle of self-describing data assets in a laboratory request-to-result workflow. Data and metadata are enriched continuously enriched along the workflow.





Curious about our products or services? Let us provide you with the answers you need. Contact us today and discover how we can cater to your needs effectively.